DINOv3
本文详细说明如何在 NVIDIA Jetson Orin 平台部署Meta 2025年发布的 DINOv3 超级视觉基础模型,涵盖模型介绍、系统要求、热力图可视化及视频流无监督分割两个核心应用案例,帮助开发者快速上手并理解DINOv3的视觉表征能力。
1. 概览
DINOv3是基于 自监督学习+Gram anchoring 技术的视觉Transformer(ViT)模型,相比DINOv2、MoCo等前代模型,在特征提取的泛化性、密集特征质量及空间结构理解能力上有显著提升。其核心参数与优势如下:
● 参数量 :提供7B(70亿参数)等多规格,适配不同计算资源需求;
● 训练数据 :基于17亿张图片的超大规模数据集(如LVD-1689M),覆盖丰富场景;
● 核心技术 :Gram anchoring机制强化特征间关系建模,解决传统ViT的局部特征弱问题;
● 功能特性 :支持 多任务(分类、分割、检测)、多分辨率(输入尺寸灵活)、密集特征提取(逐patch特征输出) ;
● 性能优势 :在ImageNet、COCO等基准数据集上,分类、分割任务性能全面超越;
| 方法 | 优势 | 局限性 |
|---|---|---|
| MoCo/SimCLR | 简单高效,个体判别 | 局部特征弱 |
| iBOT/BEiT/MAE | inpainting任务,密集特征强 | 全局一致性不足 |
| DINOv2 | 自蒸馏+对比学习,性能强 | 大模型(如ViT-L)密集特征退化 |
| DINOv3 | Gram anchoring,极大规模,密集特征优 | 训练资源需求极高 |
2. 环境准备
硬件需求
| 组件 | 要求 |
|---|---|
| 设备 | Jetson Orin(Nano / NX / AGX) |
| 内存 | ≥ 8GB(更大模型需更高内存) |
| 存储空间 | ≥ 64GB(取决于模型大小) |
| GPU | 支持 CUDA 的 NVIDIA GPU |
软件需求
- Ubuntu 20.04 / 22.04(建议使用 JetPack 5.1.1+)
- NVIDIA CUDA 工具包和驱动(JetPack 已预装)
- Docker(可选,用于容器化部署)
⚙️ 使用
jetson_clocks和检查nvpmodel,启用最大性能模式以获得最佳推理效果。
3. 基于DINOv3的Patch特征热力图可视化案例
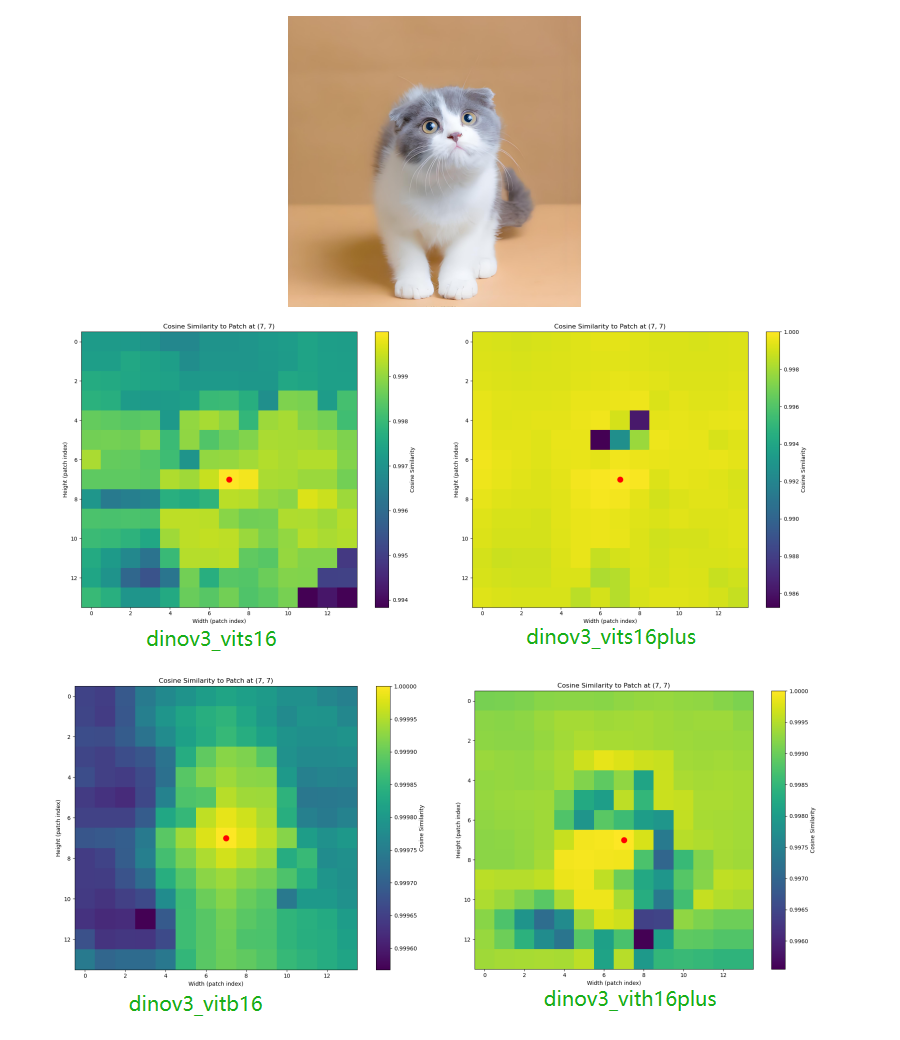
本案例通过 DINOv3提取图像patch特征 ,计算指定patch与其他patch的 余弦相似性 ,生成热力图展示模型对图像空间结构的理解能力(如物体部件关联、轮廓边界等)。
3.1 系统环境安装
安装JetPack SDK及Python核心依赖,确保环境兼容性:
sudo apt update
sudo apt install python3-pip git -y
pip3 install --upgrade pip
pip3 install pillow transformers accelerate modelscope opencv-python tqdm addict simplejson sortedcontainers
pip install numpy==1.24.4
pip install "pyarrow==12.0.1"
pip install "modelscope[datasets]"
3.2 获取DINOv3源码
获取Facebook Research官方仓库,获取模型框架代码:
git clone https://github.com/facebookresearch/dinov3.git
cd dinov3
3.3 创建热力图可视化测试代
新建test_dinov3目录及dinov3_vision_test.py文件,指令如下
# 新建工作目录
mkdir test_dinov3
cd test_dinov3
# 编辑测试代码
vim dinov3_vision_test.py
代码示例如下:
注:如需切换 DINOv3 不同模型(ViT Small/Base/Large、ConvNeXT),请参考下表修改模型导入和实例化代码。权重文件也需与模型类型对应,否则会报错。(如需使用更多模型架构定义,可以参考dinov3/models/vision_transformer.py)
| 模型类型 | 导入方式 | 实例化方式 |
|---|---|---|
| ViT Small | from dinov3.models.vision_transformer import vit_small | model = vit_small(patch_size=16) |
| ViT Base | from dinov3.models.vision_transformer import vit_base | model = vit_base(patch_size=16) |
| ViT Huge | from dinov3.models.vision_transformer import vit_huge2 | model = vit_huge2(patch_size=16) |
import torch
import torchvision.transforms as transforms
import torch.nn.functional as F
import matplotlib.pyplot as plt
from PIL import Image
import argparse
import os
# 1. 导入模型结构,
from dinov3.models.vision_transformer import vit_base
def compute_patch_similarity_heatmap(patch_features, H, W, target_patch_coord):
target_idx = target_patch_coord[0] * W + target_patch_coord[1]
target_feature = patch_features[0, target_idx]
similarities = F.cosine_similarity(
target_feature.unsqueeze(0),
patch_features[0],
dim=1
)
heatmap = similarities.reshape(H, W).cpu().numpy()
return heatmap
def plot_similarity_heatmap(heatmap, target_patch_coord, save_path=None):
H, W = heatmap.shape
fig, ax = plt.subplots(figsize=(10, 8))
im = ax.imshow(heatmap, cmap='viridis', aspect='equal')
ax.plot(target_patch_coord[1], target_patch_coord[0], 'ro', markersize=10)
plt.colorbar(im, ax=ax, label='Cosine Similarity')
ax.set_xlabel('Width (patch index)')
ax.set_ylabel('Height (patch index)')
ax.set_title(f'Cosine Similarity to Patch at {target_patch_coord}')
plt.tight_layout()
if save_path:
plt.savefig(save_path)
print(f"Heatmap saved to {save_path}")
else:
plt.show()
plt.close(fig)
return fig, ax
def main(image_path, model_path, patch_size=16, input_size=224, output_path="patch_similarity_heatmap.png"):
# 1. 加载图片
image = Image.open(image_path).convert("RGB")
transform = transforms.Compose([
transforms.Resize((input_size, input_size)),
transforms.ToTensor(),
])
tensor_image = transform(image).unsqueeze(0) # (1, 3, H, W)
# 2. 加载模型结构和权重
#model = vit_small(patch_size=patch_size)
model = vit_base(patch_size=patch_size)
state_dict = torch.load(model_path, map_location="cpu")
model.load_state_dict(state_dict, strict=False)
model.eval()
if torch.cuda.is_available():
model.cuda()
tensor_image = tensor_image.cuda()
# 3. 提取 patch 特征并可视化
with torch.no_grad():
features_dict = model.forward_features(tensor_image)
patch_features = features_dict["x_norm_patchtokens"]
num_patches = patch_features.shape[1]
H = W = int(num_patches ** 0.5)
target_patch_coord = (H // 2, W // 2) # 选中心patch
heatmap = compute_patch_similarity_heatmap(patch_features, H, W, target_patch_coord)
plot_similarity_heatmap(heatmap, target_patch_coord, save_path=output_path)
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--image', type=str, required=True, help='Path to input image')
parser.add_argument('--model', type=str, required=True, help='Path to DINOv3 .pth model')
parser.add_argument('--patch_size', type=int, default=16, help='Patch size (default=16)')
parser.add_argument('--input_size', type=int, default=224, help='Input image size (default=224)')
parser.add_argument('--output', type=str, default='patch_similarity_heatmap.png', help='Output heatmap image path')
args = parser.parse_args()
main(args.image, args.model, args.patch_size, args.input_size, args.output)
3.4 获取预训练模型
DINOv3提供多种架构(ViT Small/Base/Large、ConvNeXT)及训练集(LVD-1689M、SAT-493M)的预训练权重,可从Hugging Face。常用模型如下:
3.5 测试验证
运行以下命令,生成指定图像的热力图(以ViT Base模型��为例):
python dinov_vision_test.py --image test.png --model dinov3_vits16_pretrain_lvd1689m.pth --output patch_similarity_heatmap.png
● --image: 输入图片的路径。
● --model: 选择的DINOv3模型。
● --output: 输出的热力图文件路径。
输出结果如下:
输出的 patch_similarity_heatmap.png 热力图,直观反映指定 patch 与其它 patch 的相似性,体现 DINOv3 对空间结构的理解能力。
4. 基于DINOv3+KMeans的视频流无监督分割案例
本案例结合DINOv3的 patch特征提取能力 与 KMeans聚类算法 ,实现Jetson Orin NX+imx219摄像头的 实时视频无监督分割 ,无需人工标注即可将视频帧分为前景、背景等区域。
4.1 原理简介
-
DINOv3:是一种自监督视觉Transformer(ViT)模型,能够学习到丰富的视觉结构特征。
-
KMeans 聚类:对每一帧图像的 patch token 特征进行无监督聚类,将每个 patch 分配到若干类别,实现区域分割。
-
工作流程:
-
IMX219摄像头采集视频帧
-
用 DINOv3 提取 patch 特征
-
对特征做 KMeans 聚类
-
聚类结果可视化叠加到原图
-
4.2 环境准备
系统安装:
安装依赖库,支持Scikit-learn聚类及PyTorch模型推理:
pip install scikit-learn Pillow
硬件安装:
将 IMX219 摄像头连接至设备(注意:请确保摄像头排线的金属片朝上)。

4.3 获取 DINOv3 源码
同3.2节,克隆dinov3仓库并进入项目目录。
4.4 创建视频流无监督分割测试代码
新建test_dinov3目录及dinov3_kmeans_test.py文件,编写以下代码:
# 新建工作目录
mkdir test_dinov3
cd test_dinov3
# 编辑测试代码
vim dinov3_kmeans_test.py
代码示例如下:
注:如需切换 DINOv3 不同模型(ViT Small/Base/Large、ConvNeXT),请参考下表修改模型导入和实例化代码。权重文件也需与模型类型对应,否则会报错。(如需使用更多模型架构定义,可以参考dinov3/models/vision_transformer.py)
| 模型类型 | 导入方式 | 实例化方式 |
|---|---|---|
| ViT Small | from dinov3.models.vision_transformer import vit_small | model = vit_small(patch_size=16) |
| ViT Base | from dinov3.models.vision_transformer import vit_base | model = vit_base(patch_size=16) |
| ViT Huge | from dinov3.models.vision_transformer import vit_huge2 | model = vit_huge2(patch_size=16) |
import cv2
import torch
import torchvision.transforms as transforms
import numpy as np
from sklearn.cluster import KMeans
import time
from dinov3.models.vision_transformer import vit_base
def preprocess_frame(frame, input_size):
# OpenCV BGR to RGB
frame_rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
pil_img = transforms.ToPILImage()(frame_rgb)
transform = transforms.Compose([
transforms.Resize((input_size, input_size)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
tensor_img = transform(pil_img).unsqueeze(0)
return tensor_img
def segment_with_kmeans(patch_features, H, W, n_clusters=3):
# patch_features: [1, num_patches, dim]
features = patch_features[0].cpu().numpy() # [num_patches, dim]
# 聚类
kmeans = KMeans(n_clusters=n_clusters, n_init=1, max_iter=50, random_state=0)
labels = kmeans.fit_predict(features)
mask = labels.reshape(H, W)
return mask
def mask_to_color(mask, n_clusters):
# 将聚类标签转为彩色 mask
mask_norm = np.uint8(255 * mask / (n_clusters - 1))
mask_color = cv2.applyColorMap(mask_norm, cv2.COLORMAP_JET)
return mask_color
def main(model_path, patch_size=16, input_size=224, n_clusters=3):
# 1. 加载模型
model = vit_base(patch_size=patch_size)
state_dict = torch.load(model_path, map_location="cpu")
model.load_state_dict(state_dict, strict=False)
model.eval()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# 2. 打开摄像头
gst_pipeline = (
"nvarguscamerasrc ! "
"video/x-raw(memory:NVMM), width=(int)1280, height=(int)720, format=(string)NV12, framerate=(fraction)30/1 ! "
"nvvidconv ! "
"video/x-raw, format=(string)BGRx ! "
"videoconvert ! "
"video/x-raw, format=(string)BGR ! "
"appsink"
)
cap = cv2.VideoCapture(gst_pipeline, cv2.CAP_GSTREAMER)
if not cap.isOpened():
print("Error: Camera not opened")
return
print("Camera opened successfully! Press 'q' to quit.")
while True:
t0 = time.time()
ret, frame = cap.read()
if not ret:
print("Can't receive frame. Exiting ...")
break
# 3. 预处理
tensor_frame = preprocess_frame(frame, input_size)
tensor_frame = tensor_frame.to(device)
# 4. DINOv3 特征提取
with torch.no_grad():
features_dict = model.forward_features(tensor_frame)
patch_features = features_dict["x_norm_patchtokens"] # [1, num_patches, dim]
num_patches = patch_features.shape[1]
H = W = int(num_patches ** 0.5)
# 5. KMeans 聚类分割
mask = segment_with_kmeans(patch_features, H, W, n_clusters=n_clusters)
# 6. mask 彩色化并resize
mask_color = mask_to_color(mask, n_clusters)
mask_resized = cv2.resize(mask_color, (frame.shape[1], frame.shape[0]), interpolation=cv2.INTER_NEAREST)
# 7. 叠加显示
overlay = cv2.addWeighted(frame, 0.6, mask_resized, 0.4, 0)
# 8. 帧率显示
fps = 1.0 / (time.time() - t0)
cv2.putText(overlay, f"FPS: {fps:.2f}", (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
cv2.imshow('DINOv3 + KMeans Unsupervised Segmentation', overlay)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
if __name__ == '__main__':
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('--model', type=str, required=True, help='Path to DINOv3 .pth model')
parser.add_argument('--patch_size', type=int, default=16, help='Patch size (default=16)')
parser.add_argument('--input_size', type=int, default=224, help='Input image size (default=224)')
parser.add_argument('--n_clusters', type=int, default=3, help='Number of clusters for KMeans')
args = parser.parse_args()
main(args.model, args.patch_size, args.input_size, args.n_clusters)
4.5 获取预训练模型
KMeans分割案例需使用 ViT Base/Large 等模型的预训练权重(与热力图案例通用)。下载链接同3.4节。
4.6 测试验证
运行以下命令,启动实时视频分割(以ViT Base模型、2个聚类类别为例):
python test-dinov3-kmeans.py \
--model dinov3_vitb16_pretrain.pth \
--patch_size 16 \
--input_size 224 \
--n_clusters 2
-
--model:指定 DINOv3 的权重文件路径,必须与模型结构对应(如 vit_base 用 vitb16 权重)。
-
--patch_size:patch 大小,通常为16。
-
--input_size:输入图片 resize 大小,通常为224。
-
--n_clusters:KMeans 聚类分割的类别数,2表示前景/背景分割,3及以上可尝试更多区域。
效果展示如下,对视频中的物品进行无监督的识别,可以有效得将实时视频无监督分割 ,无需人工标注即可将视频帧分为前景、背景等。
